Convolution Neural Network vs Fully connected Neural Network
Translation invarient
Sparsity of connection
Sharing of parameter
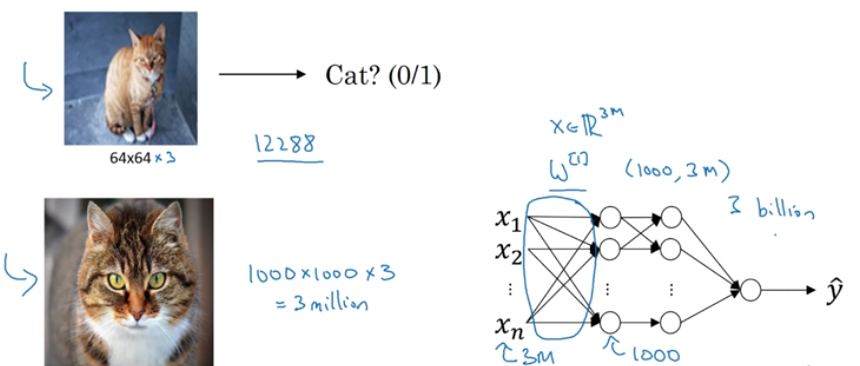
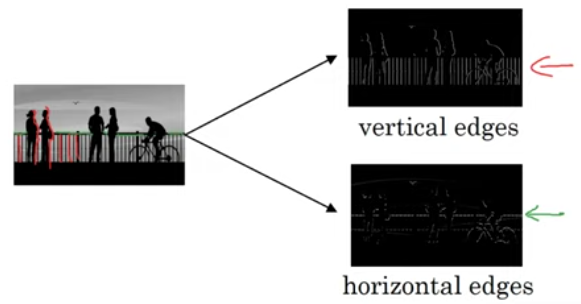
Image processing edge detection:
Grey scale input \(*\) kernal/filter (3x3 filter)
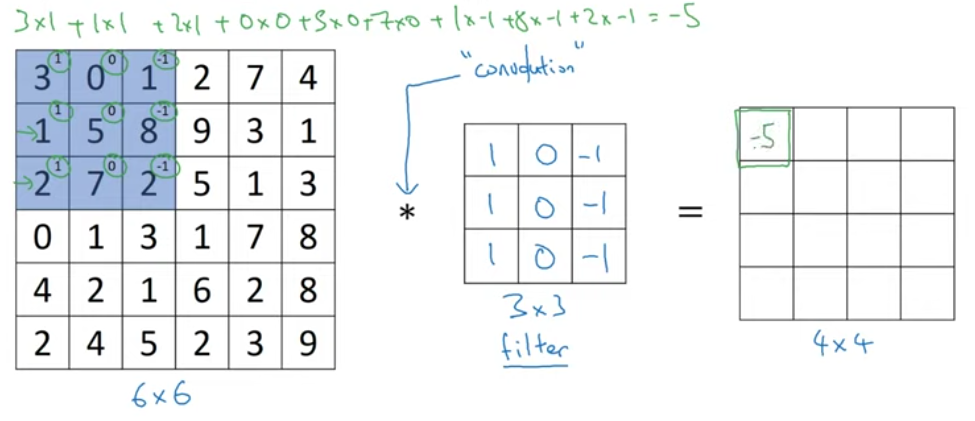
> 1) shape of the output is \(6 - 3 + 1 = 4\)
> 2) channel vise convolution operation
> 3) like wise move the filter position by 1 on x axis
> 4) repeate 3) until the end and then one step down like below.
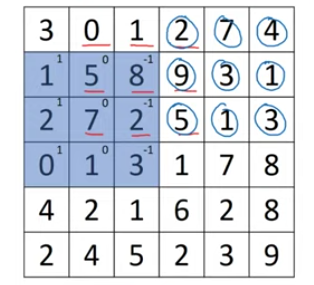
> 5) follow the above step till the end.
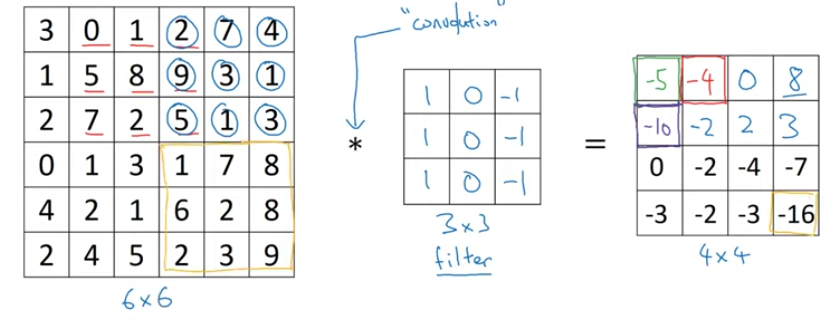
> Technically this is called cross-correlation and convolution in technical terms will have 2 step preseding (but not used in practice). > 1) Mirror of filter Horizontally and then > 2) Mirror of filter Verfically.
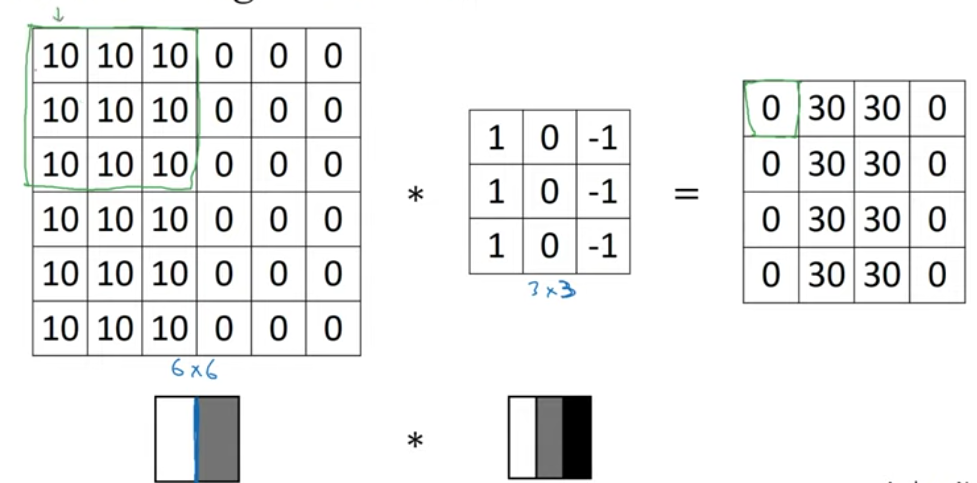
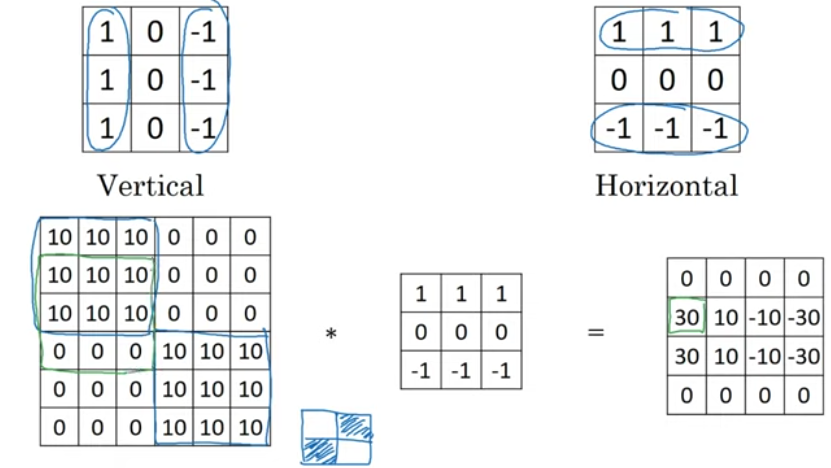
Vertical edge detector
Horizontal edge detector
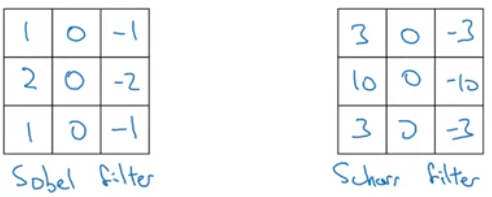
Sobel/Schar filter
Learnable filter
These parameters can learn through backpropagation/gradient decent the necessary filters that can better map the complex funtion.
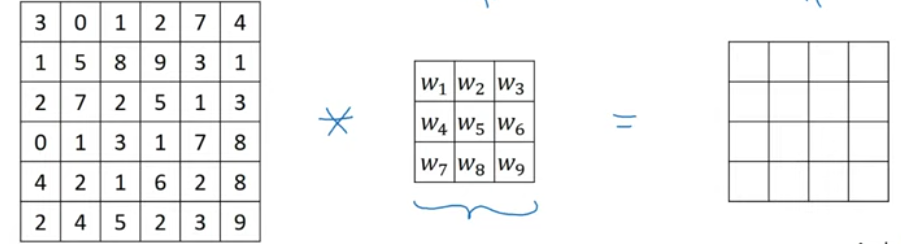
> usually the filter sizes are odd, 1x1, 3x3, 5x5, 7x7x (comes from computer vision letrature)
Athough with input with more than 1 channel, the channel size of the kernal will match the input channel.
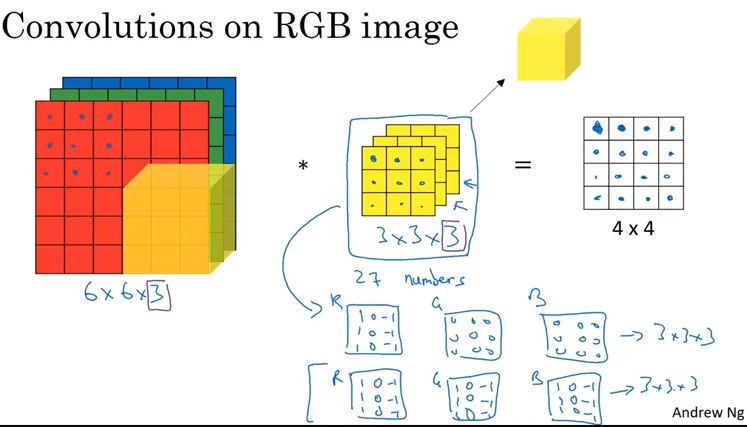
Likewise there will be many such filters learning multiple low level features with learnable parameter.
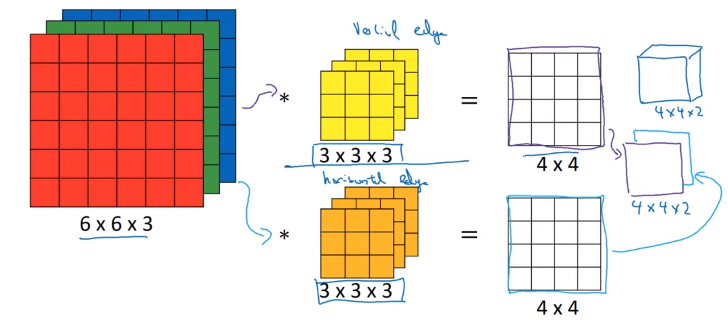
> Note; the output channel will be based on the number of filter.
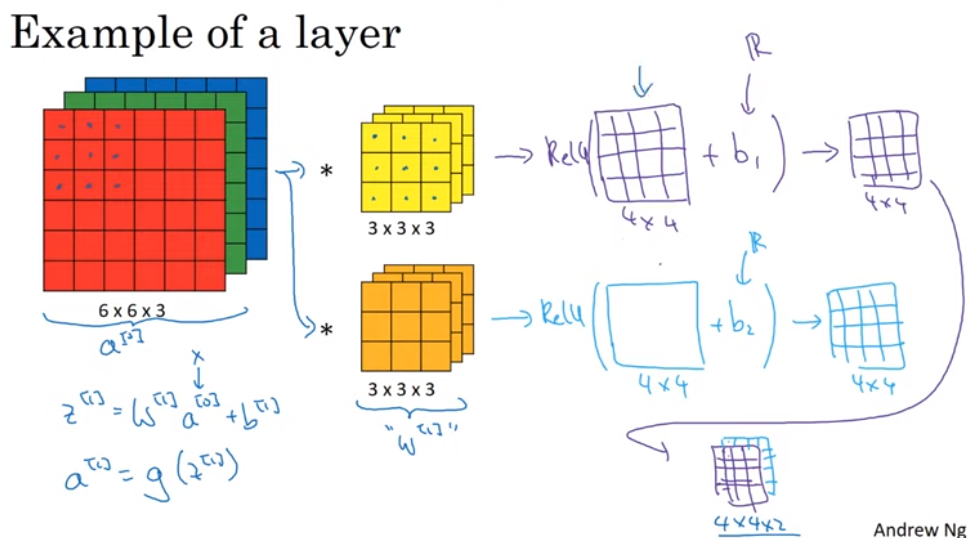
The number of parameters = \(n * (k ^2 * c + 1)\)
- n is the number of filter
- k is the kernel size
- c is the channel size
filter: k x k x n_c (number of channel from the input) activation: n_h x n_w x n_f (number of filter) weights: k x k x c x n_f bias: 1 x 1 x 1 x n_f
Padding
- Avoids strinking of output
- Input in the edges are given priority
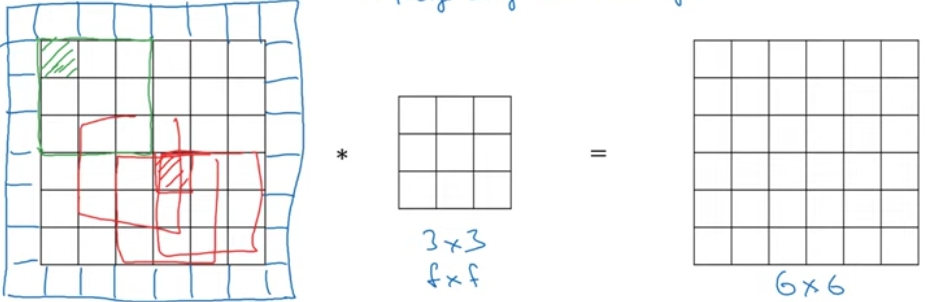
- Valid convolution: no padding (where p = 0)
- Same convolution : padding to provide output shape same as input (where \(p = \frac {f-1} 2\)).
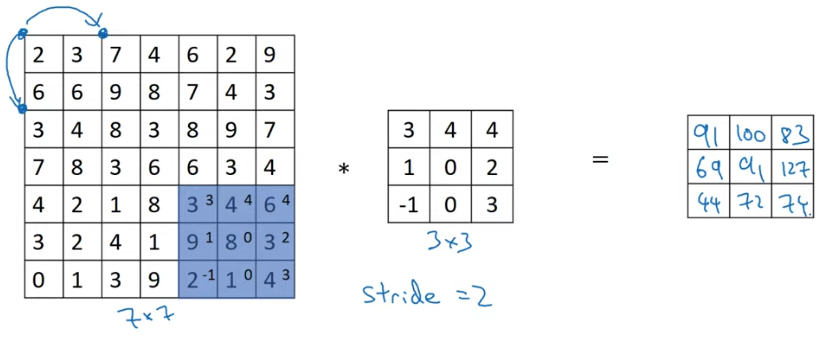
\[ \lfloor {\frac {input size + (2 * padding) - filter size} {strides} + 1}\rfloor \]
> If not an integer, should round it down (floor)
Strides
Pooling
- Max pooling for filter size 2 and stride 2.
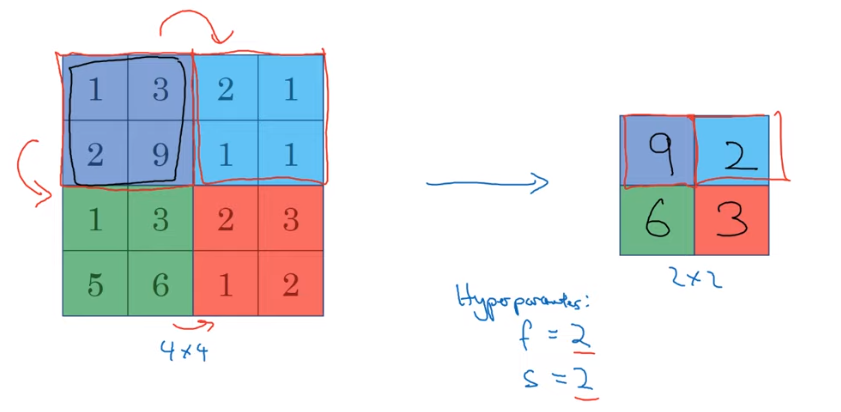
> Note; > 1) Max pool operation is done on a per channel basis, so for \(n\) dimentions, the output will also be \(n\). > 2) There is no learnable parameter for this layer.
Like wise there is average pooling (although its not used widely) Its can be used at the deeper layers where say 7x7x1000 -> 1x1x1000 commonly used values are for; f=2, s=2 and f=3, s=2.
Fully connected
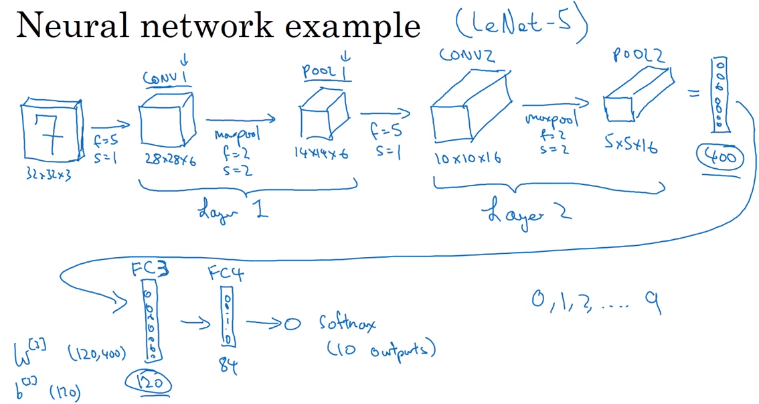
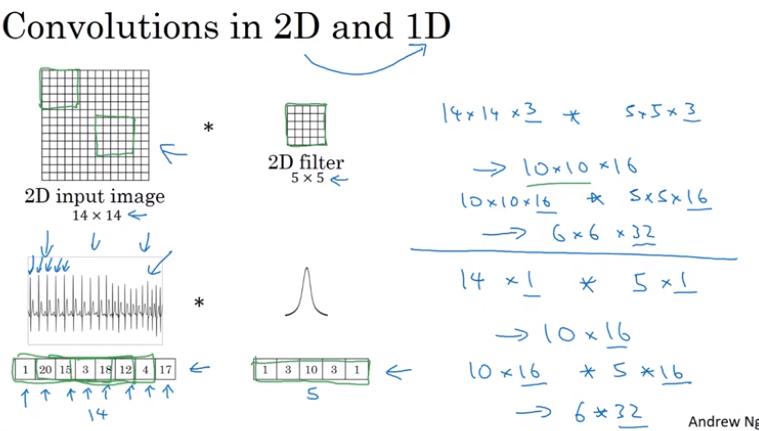
Different volumes

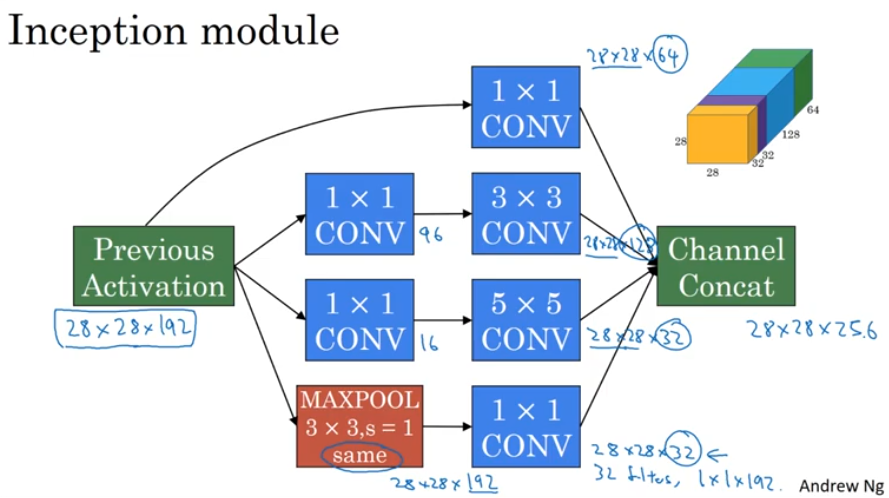
1x1 convolution
Inception
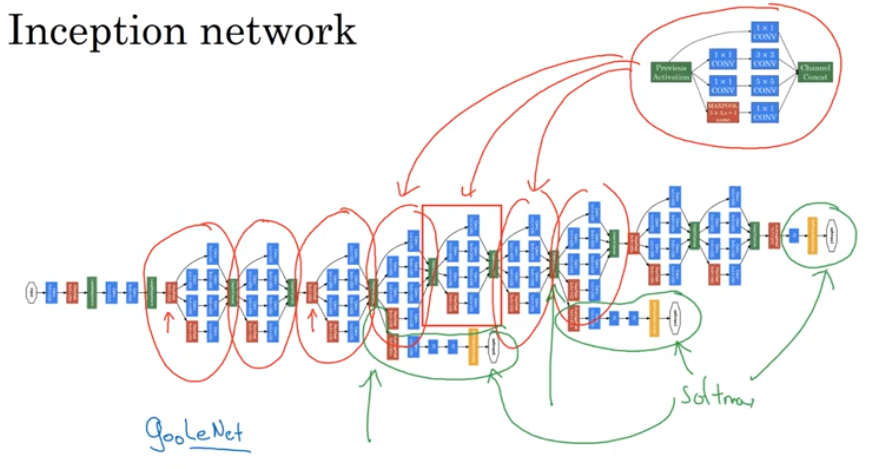
TODO sliding window with convolution
Image classification
Object localization Object detection
Image segmentation Instance segmentation
YOLO, Image segmentation 6 Dof pose estimation methods
Style transfer