Build a system first and then iteratevely improve upon the system with bias and variance/ error correct
Numpy vs Tensor
| Framework | Data structure | Property | Targets | Automatic differentiation | Data type |
|---|---|---|---|---|---|
| tensorflow | tensors | immutable | CPU/GPU/TPU | Yes | Numerical/String |
| numpy | array | mutable | CPU | No | Numerical |
- A tensor is not actually a grid of values but the computations that lead to those values
- Different type of tensors
Bias and Variance
| High varience | High bias | high bias & varience | low bias & variance | |
|---|---|---|---|---|
| tain set | low error | medium error | medium error | low error |
| val set | high error | medium error | high error | low error |
> More on that in splitting data > - Error is in respect to the bayes error (optimal error). > - Avoidable bias is the difference between bayes error and training error. > - Its not always easy to find bayes error(human level performance) on large structured dataset.
These steps help with the orthogonalization
Hight Bias? If Yes (Try training deeper models and or Longer training period or with a different Optimizer, NN architecture/hyperparameter search)Hight Variance? If Yes (Try adding more data/augmenation and or Regularization, Error analysis)If the model now doesn’t perform well on the test set, increase the validation set.
Orthogonalization
Tune one parameter at a time to have a clear view over its impact on the training process.
Hyper parameter
by the order of importance
- \(\alpha\) learning rate
- \(\beta\) momentum \(~0.9\)
- \(\beta_1 0.9, \beta_2 0.999, \epsilon 10^{-8}\) for Adam optimizer.
- Number of hidden units
- Mini-batch size
- Number of layers
- Learning rate decay
Grid search of optimal hyperparameter might not work for deeplearning, since not eache hyperparameter is equally weight in its importance.
Random sampling is good to initally figure out the area in the grid that gives good results; later on reduce the search space to this and try again more densly in this reduced space.
Ensure the scale of the hyperparameter is appropriate; for example \(\alpha\) learning rate should be in log scale.
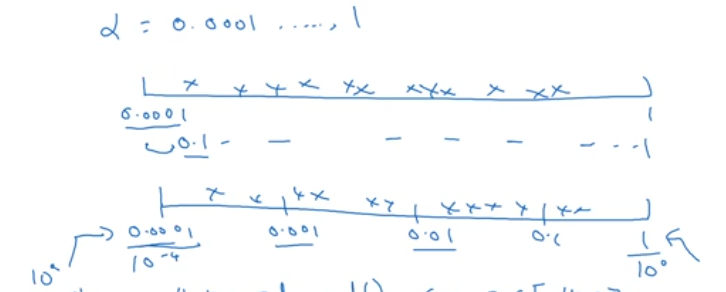
| |
Similarly for \(\beta\) its of the range \([0.9 .. 0.999]\)
\((1-\beta) = [0.1 .. 0.001]\)
and r is the range -3, -1
| |
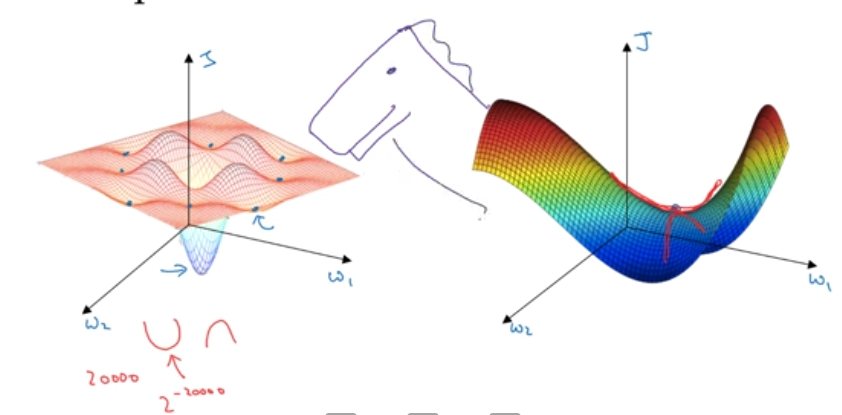
Local optima
The chances of getting gradient 0 in a higher dimention is quite small. Its mostly going to be a saddle point. (Saddle because its like on the horse)
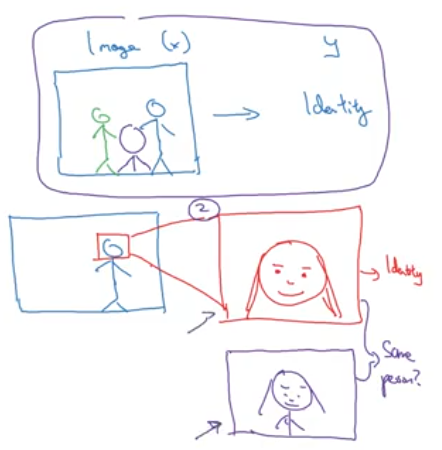
Analyse the performace
Evaluation metric
Use a single real value to evaluate the models performace quickly.
Following can be a error metric; \[ Accuracy - 0.5 * lattency\\ \frac 1 {\sum_i^{} w^{(i)}} \sum_i^{m_{dev}} w^{(i)} (y_{pred}^{(i)} \neq y^{(i)})\\ where w is 1 for x^{(i)} is non-porn 10 if x^{(i)} is porn. \] F1 score; Takes the average (Harmonic mean) of precision and recall \(\frac 2 {\frac 1 {Precision} + \frac 1 {Recall}}\)
If there are N metrics you care about,
- use 1 as the optimizer and
- N-1 as satisfier (as long as it meets some accetable threshold)
Then optimize your training for the above metic
\(J = \frac 1 {\sum_i^{m}w^{(i)}} \sum_i^{m}w^{(i)} l(\hat{y}^i, y^i)\)
Dataset
Splitting
The dataset is usually split into three.
| Splits | Small dataset | Large dataset |
|---|---|---|
| Train | 70% | 98% |
| Validation | 15% | 1% |
| Test | 15% | 1% |
> Note; since the 1% of a large dataset is enough to validation the model.
- Ensure the validation and test set come from the same distribution.
- The test set is to have an unbiased performace estimation of your model (which is not mandotory).
But when the training data is not the same distribution as the validation and test, the training data is split into
| Split | Error (in distribution A) Training data | Error (in distribution B) Real world data | Type |
|---|---|---|---|
| Human level \(\approx\) Bayes error | 4% | 6% | |
| Train | 7% | 6% | Hight Bias (7%-4% is avoidable bias) |
| Train-val | 10% | High Variance (10%-7% is vaiance) | |
| Validation | 12% | Distribution shift (12%-10%) | |
| Test | 12% | Over fitted on the validation split | |
| Distribution shift across these two colums of error |
> To find the error is due to hight varience or due to different distribution.
> Note: The different in error between train-val and validation will give the error added due to different distribution.
Error analysis
- Use confusion matrix on the validation set and or filtering the misslabeled images as below.

- Pro tip;
- Catch misslabelled ground truth is a seprate column
- Random errors on large datset is fine; only systematic errors are an issue).
- In case of misslabelled data, its wise to look at correctly predicted classes as well.
- Ensure to do the same process to your validation set as well as the test set.
Addressing data mismach
- Making training data more similar (data synthesis) and or collecting more data similar to validation/ test sets.
Transfer learning
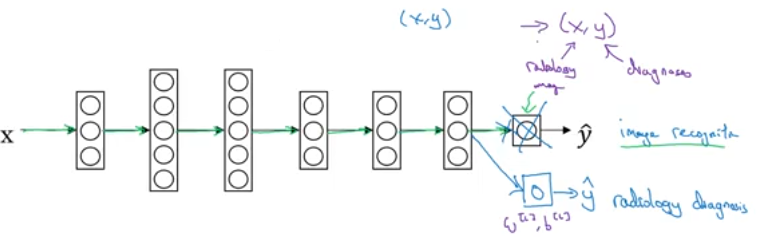
When you have trained a large set of data on a deep learning model you can expect the initial layers will learn useful features that can be reused for other similar task. For example
Using the features from the model trained on large imagenet dataset
\(\color{blue}{x,y}\) to retrain on small radiology dataset
\(\color{purple}{x,y}\) by replacing the final layers with one or more
layers to predict the \(\color{purple}{\hat{y}}\)
Note;
- Pretraining is on the \(\color{blue}{x,y}\) and
- Fintuning is on the \(\color{purple}{x,y}\) .
Muititask learning
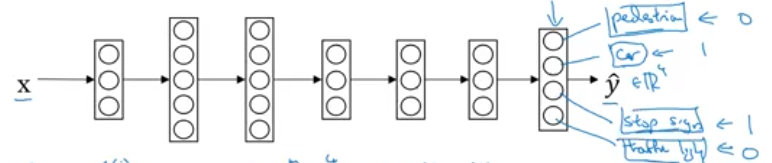
\(y^{(i)}\) will be \([0,1,1,0]\)
\[ J = \frac 1 {m} \sum_{i=1}^m \sum_{j=1}^{number of class} L(\hat{y}_j^i, y_j^i) \] > when there is missing label data for some class you should only consider summing over the classes where there is label 0/1 in the cost funtion.
where the loss funtions is same as logistic loss.
Tips for training a multitask learning model;
- Ensure sharing of low features benefits in training the model recognising different tasks.
- Would need a big model to train well on all the task else the performace will get a hit.
- There should be similar amount of data for each task.
End to end approach
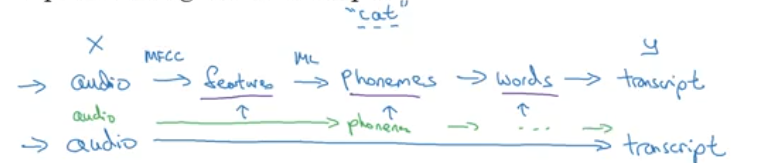
When you have enough data to map a complex funtion from input to output, an end to end deeplearning approach can be used, rather than hand designed feature.
This is not always straight forward, it differs from application to applicaiton.
- Speech recognition example:
- Face recognition example: